
 The last couple blog posts I have written have not been technical in nature, and given the information I originally intended to be discussed on this blog (testing at startups), I feel compelled to discuss a subject near and dear to me, UI testing. More specifically, I will discuss how I have implemented a sustainable UI testing framework with low maintenance that is specifically designed to avoid the pitfalls commonly associated with UI testing.
The last couple blog posts I have written have not been technical in nature, and given the information I originally intended to be discussed on this blog (testing at startups), I feel compelled to discuss a subject near and dear to me, UI testing. More specifically, I will discuss how I have implemented a sustainable UI testing framework with low maintenance that is specifically designed to avoid the pitfalls commonly associated with UI testing.
After many experiences with UI testing in various incarnations, I have found there are many ways UI automation can cause issues:
• Test cases turn into an unmaintainable mess when a site redesign happens
• Assumptions made become invalid when the performance profile of your page changes
To solve these issues, we will apply some principles from model-based testing (an approach to testing state-based systems that I have used in the past). Before discussing how this works though, it is worth mentioning that there are some situations where UI testing is not likely to work and should be avoided.
Background & Considerations
When I implemented my first UI testing framework, my inclination was to test as much as possible using it. From my naïve perspective, what better way to verify what the customers are seeing than to test it using the same medium that they were using, a browser?
While this is true for certain conditions, there are obvious reasons you would not want to do this. To begin with, UI testing is by nature slower than testing at lower levels, and every test that you add at the UI level that could do at a lower level will increase the amount of time it will take to run your test suite. It also takes more time to identify the root cause of bugs your tests find (especially if you have a complex architecture that transforms data several times before it reaches the UI) not to mention the time it takes to confirm that the problem is not an issue with the test (as sometimes, UI tests can be brittle).
Those are two compelling reasons to try to cover as much functionality at a lower level than the UI as possible, but I will argue that there is a more important reason. I would argue against UI testing something that could be tested at a lower level because writing lower level tests requires you to build testability into your architecture and will ultimately enable you and your fellow developers to proactively write targeted tests that can be run at a higher frequency and with lower maintenance cost than UI tests.
Now that we’ve established some areas where UI testing is not always the best option, there are conditions where testing the UI is very useful. Some examples of these are end user scenarios that involve multiples systems and/or multiple pages, pages that rely heavily on JavaScript, and scenarios that persist state from your site to a third part site where you may not have the luxury of an API. There are many other situations as well, so it is helpful to think of this less as a set of rules of when you should or should not UI test and rather a tradeoff to be considered. On one hand, testing at lower levels offers speed, precision, and easy of reuse; whereas, UI testing offers the ability to test multiple systems and similarity of your tests to what users will observe.
The Problems with UI Testing
Anyone who has implemented UI tests is probably familiar with how brittle they can be. The most prevalent of the factors that contribute to their brittleness (and the ones I will be addressing in this article) are:
1. They are bound to the structure of markup and commonly break when the content is rearranged.
2. They are prone to “timing issues” and mysteriously fail (especially with asynchronous page elements)
We will now talk about how to mitigate these issues. The approaches below use Java and Selenium, but other frameworks can also be adapted to this architecture.
Tests Break When Content is Re-arranged
Due to the nature of how most UI test frameworks locate page objects referenced within each test (with Selenium, it is by xpath unless you are fortunate enough to have an “id” attribute for every element you interact with), when items on a page are moved around, your previous xpath expressions are sometimes no longer valid, and as a result, those test cases cannot find the objects on the page.
Depending on how many items on the page changed and how many scripts access these page items, you may find it quite a daunting task to update all these tests each time the pages are updated. This can be mitigated to some extent by assigning as many page objects as possible “id” attributes in the page source for unique identification, or by working with your developers to develop guidelines for testability (which is a good practice anyway), but eventually, there will be situations where this is not possible.
To mitigate the impact of this, I have used the approach of abstracting the system being tested using a series of enumerations that map descriptive names to the locators. Then the UI test framework uses this abstraction to find the elements necessary for interaction. Here is a specific example of this:
public enum ProductPage implements IPageModel {
BACK (By.id("back_link")),
TRACK (By.className("track_link")),
BROWSE(By.id("browse_callout")),
TITLE(By.xpath("//*[contains(@class,'productDetails')]/h1")),
SUBTITLE(By.xpath("//*[contains(@class,'productDetails')]/h2")),
PRICE(By.className("basePrice"))
;
private By locator;
ProductPage(By locator){
this.locator=locator;
}
public By getLocator(){
return this.locator;
}
}
To utilize this technique, you can simply import all of the enums for the pages you interact with, and then you can refer to items on the page with descriptive names like “ProductPage.TITLE”instead of “//*[contains(@class,’productDetails’)]/h1” which is more readable in your test anyway. The benefit to this approach is that a page element that is accessed in 20 different scripts, only needs to change the value in the enumeration and none of the tests themselves need to be modified. These enums are effectively a model of the system under test (and is also one key aspect of the model-based testing approach I mentioned earlier and will be further explained later).
I have also heard some people using recorders such as the Selenium IDE for this with the idea being that instead of having to maintain all of these expressions, you can just re-record the script when something changes. To me, having to re-create your tests when things change is neither preferable nor sustainable especially if you created a lot of scripts. In addition, the xpath expressions that the IDE or any other xpath generator I have seen outputs are more likely to break than manually vetted xpath expressions. These automatic xpath expressions are likely to be something like “/div[2]/div[1]/h1[2]” instead of “//h1[contains(@class,’someClass’)]” which means that any change in any of the containing divs will break the xpath expression, not just changes to the element itself.
My advice is to stay away from recorders like this as they usually end up wasting more time than they can save in the long run. Also, it is helpful to modify automated xpath expressions so they rely on the least possible number of elements (similar to the example given above contrasting the automated and manually generated xpath expressions).
Tests Have “Timing Issues”
When interacting with a website in a browser, different pages on a site and objects on those pages load at different speeds depending on a number of factors. Adding a layer of JavaScript that interacts with this page or interacting with the browser through an API as with UI testing frameworks, adds further complexity. The difficult truth that I have observed with UI tests is that when written in a conventional nature, things just fail seemingly at random because of these layered complexities.
Some try to mitigate these issues by taking the approach of putting try-catch blocks around problematic aspects of their code, but this ends up being unmaintainable and even messy as more and more random failures emerge. Even the most committed of those implementing UI automation sometimes say “I don’t know why it failed; it does that sometimes. Run it again.”
The true nature of this general error-handling problem can be divided into 2 sub-problems:
1. Non-specific failures related to timing of page objects and the architecture itself
2. Specific problems that happen when transitioning from one state to another
For the first problem, I am going to argue the following: every single action you do on a UI test should have a standardized retry mechanism.
We are not doing performance testing here; if you have concerns about a page item being slow to return, you should write a test specifically for that. In all other cases, if you cannot find a page object, trying again n number of times will not make the test falsely pass, but it will filter out false positives for test failures. Also, with Selenium, if you attempt to retrieve a page object and it is not there, it throws an error. I recommend always ignoring this error (by writing a method interceptor for it that categorically has an empty try-catch around it… I’ll give an example below).
If the page object is really necessary for what you are trying to accomplish in you test, the test will fail when it tries to perform an action involving the object. Essentially, your test should be as specific as possible, and also control for extraneous variables such as performance, complexities with loading page objects, and test framework issues at a global level. Any exceptions not related to things you are proactively asserting in your test can be logged and should not cause the test to fail. This approach will make your tests more specific and actionable instead of trying to test 100 different things in one test then being bogged down by random failures as described above.
To implement a standard, global retry mechanism (and by virtue of the implementation, a way to create your own custom methods for the object representing the page element you are interacting with) you can creatively put reflection to use. I used a modified version of the reflection-based proxy that Jakob Jenkov mentioned in a blog post of his. What I did was define a class “Get” that has a static method returning a WebElement object. Therefore, to get an instance of a WebElement to interact with you can write “Get.webElement(driver, HomepageModel.SOME_LINK.getLocator())” instead of “driver.findElement(HomepageModel.SOME_LINK.getLocator())”. You can trace how this will work on the example code below.
The obvious benefits of this method are 1) you get error handling for common timing issues for free (as the retry logic for all WebElements is defined CustomWebElement as well as the option for configurable timeouts for retrieving objects in the Get class) making it so you don’t need to mess around with repetitive try-catch blocks everywhere in your test cases and 2) because you are interacting with a proxy object through an interface, you can add custom methods to the interface (IExtendedWebElement) that have not been implemented and implement them in the CustomWebElement class (see the commented out code for the method “customMethodName”). Here is the code for this example:
public class Get {
public static IExtendedWebElement webElement(WebDriver driver, By locator, int millisToWait){
WebElement we = waitForElement(driver, locator, millisToWait);
return (we == null)? null : CustomWebElement.createWrapperSeleniumInstance(we);
}
private static WebElement waitForElement(WebDriver driver, By locator, int timeoutmillis){
WebElement element = null;
element = findElementWithoutComplaints(driver, locator);
boolean foundElement = (element != null && element.isDisplayed());
int elapsedMillis = 0;
while(!foundElement && elapsedMillis < timeoutmillis){
element = findElementWithoutComplaints(driver, locator);
foundElement = element != null && element.isDisplayed();
try {
Thread.sleep(100);
}catch (InterruptedException e){
e.printStackTrace();
}
elapsedMillis+=100;
}
return (element != null && element.isDisplayed()) ? element : null ;
}
private static WebElement findElementWithoutComplaints(WebDriver driver, By locator){
try{
return driver.findElement(locator);
}catch(Exception e)
{ return null; }
}
}
public interface IExtendedWebElement extends WebElement {
// public boolean customMethodName(int iArg);
}
public class CustomWebElement implements InvocationHandler {
private WebElement element;
private static final int SLEEP_MS = 500;
private static final int RETRY_COUNT = 2;
public CustomWebElement(WebElement element){
this.element = element;
}
public static IExtendedWebElement createWrapperSeleniumInstance(WebElement toWrap) {
return (IExtendedWebElement)(Proxy.newProxyInstance(IExtendedWebElement.class.getClassLoader(), new Class[]{IExtendedWebElement.class}, new CustomWebElement(toWrap)));
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable{
int numRetries = 1;
try{
// if("CUSTOMMETHODNAME".equals(method.getName().toUpperCase())){
// return this.customMethodName((Integer)args[0]);
// }
return method.invoke(element, args);
}catch(InvocationTargetException ite){
ite.printStackTrace();
while(numRetries System.out.println("Retrying because of error...");
try{
numRetries++;
Thread.sleep(SLEEP_MS);
return method.invoke(element, args);
}catch(Exception e){
if(numRetries == RETRY_COUNT){
if(null != ite.getCause()){
throw ite.getCause();
}else{
throw ite;
}
}
}
}
}
return null;
}
}
For the second issue about specific problems that happen when transitioning from one state to another during a test, these can be mitigated with further application of another component of model-based testing, as described below.
Putting it All Together
Model-based testing describes systems as having a series of states and also transitions between these states.
In my description so far, we have covered the idea of “states” by loosely defining each page on the website under test as a different state and then modeling it with enumerations. However a state is not limited to page changes, but multiple states that can be achieved by performing actions within the same page. This gets to the last piece of the architecture, which is defining the “paths” or transitions from one state to another.
Since it is likely that within multiple tests you will perform the same transitions from one state to another (for instance, execute a search), it is understandable that you don’t want to implement the same step over and over again in every test. Thankfully this is where inheritance can be your friend. It helps to think of the definition of your website as a series of states (the page enumerations) and a series of possible transitions between states that are then shared by all test cases you write (defined in an abstract super-class that all tests inherit from). Here is a diagram of what I am referring to:
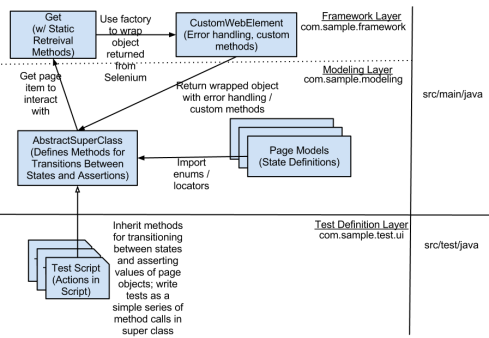
After you have defined how to move between states in the abstract superclass, test cases are very easy to write and infinitely more readable. For instance, here is a partial example of an abstract superclass that defines state transitions and a derived test case; take special note that the test case needs no information about the system under test (defined in the abstract super class / page enumerations) nor does it need to implement error handling (done in the CustomWebElement class), it simply is a list of steps and assertions:
public class MobilePrototypeTest extends AbstractMobileTestCase{
@Test
public void testAlerts() throws MalformedURLException {
TransitionHomeToLoggedInState(false);
AssertLoggedIn();
}
}
public class AbstractMobileTestCase {
protected void TransitionHomeToLoggedInState(boolean hasFacebookCookie){
Get.webElement(driver, MobileHomepageModel.TRACK.getLocator(),2000).click();
if(Get.webElement(driver, MobileFacebookPopupModel.FACEBOOK_BUTTON.getLocator(),1000) != null){
Get.webElement(driver, MobileFacebookPopupModel.FACEBOOK_BUTTON.getLocator()).click();
}
if(!hasFacebookCookie){
doFacebookSignin();
}
}
protected void AssertLoggedIn(){
// put your verification logic here
}
private void doFacebookSignin(){
Sleeper.sleepTight(2000);
try{
if(driver.getWindowHandles().size() > 1){
driver.switchTo().window("Log In | Facebook");
Sleeper.sleepTight(500);
}
}catch(Exception e){
// Sometimes switchTo returns an error, yet still works. there is no harm in dismissing the
// error with an empty catch as it will be immediately obvious if the login window is not present
// when we try to type in an email address in the next step
}
Get.webElement(driver, MobileFacebookPopupModel.EMAIL.getLocator(),7000).sendKeys(MobileFacebookPopupModel.getLoginEmail());
Get.webElement(driver, MobileFacebookPopupModel.PASSWORD.getLocator()).sendKeys(MobileFacebookPopupModel.getLoginPassword());
Get.webElement(driver, MobileFacebookPopupModel.SUBMIT.getLocator()).click();
try{
driver.switchTo().window(null);
Sleeper.sleepTight(500);
}catch(Exception e){}
}
}
As you see in the example above, the test class itself is only 7 lines long. It is human readable, and it is very clear what steps are involved in the test case; as opposed to if the test case was cluttered with all of the page level details defined in our superclass.
Also, since all of the logic that is used to log in is implemented in the abstract superclass, if there was another test case that required log in functionality, it would be easy to add one line of code in that test case (calling the “TransitionHomeToLoggedInState” method in the superclass). If something changed with how login worked, one would only have to change the abstract class and any test case that had a scenario involving login would automatically be updated.
In this code is also an example of how to deal with a specific problem that happens when transitioning from one state to another, which was eluded to in the previous section (you can see this in the code above with the “switchTo()” method in “doFacebookSignin”). Since the specific error handling is also implemented in the superclass, it mitigates having to deal with the larger problem of updating all error handling logic for all test cases that deal with login scenarios.
In my experience, using these ideas has saved a lot of time in test case authoring and maintenance. When people talk of UI automation being problematic and not having enough time to do it, they are likely suffering from some of the issues that have been outlined at the start of this post. Using a series of model-based testing principles, reflection, and inheritance as I have described above, you will find that you creating a UI test framework can be easy, useful, and mitigates a lot of the issues that have commonly plagued others.
References
Jenkov, Jakob. Java Reflection: Dynamic Proxies. Retreived May 2012 from: http://tutorials.jenkov.com/java-reflection/dynamic-proxies.html

Nice one about Scalable UI Testing with Selenium